
De ’State of Data Quality 2022’: groei en complexiteit
83% van de organisaties neemt beslissingen grotendeels op basis van data, zo blijkt uit een onderzoek van TDWI. Organisaties nemen datakwaliteit ook serieus: 97% zegt het enigszins tot extreem belangrijk te vinden. Dat is uitstekend nieuws, maar de taken blijven behoorlijk uitdagend
Naast de groei van data en datastromen, zien we dat organisaties afhankelijker zijn van meerdere databronnen, in de cloud of on-premise. Dit kan het gevolg zijn van fusies en overnames, aanhoudende groei in de loop der tijd, of toenemende toepassing van datademocratiseringstrends en nieuwe ontwikkelingen, zoals Data Mesh. Dergelijke ontwikkelingen zetten governance- en engineeringteams onder druk om hoogwaardige data te vinden en te extraheren in een steeds groter wordende oceaan van assets.
Als gevolg daarvan zoeken organisaties naar, of geven ze al prioriteit aan de implementatie van datacentrische rollen, processen en tools om de levering van hoogwaardige data te waarborgen. Dit is geweldig, maar er zit een addertje onder het gras… Het invoeren of zelfs handhaven van een handmatige aanpak van Data Quality is niet meer voldoende. In deze blog leggen we uit waarom.
Handmatig beheer van Data Quality: hoe het werkt en waarom het niet houdbaar is
Data Quality heeft vele iteraties gekend, maar een traditionele, meer handmatige aanpak is nog steeds gangbaar in veel organisaties, waaronder Fortune 500-bedrijven. Handmatige implementaties zijn afhankelijk van tools en technologieën die een aanzienlijke codeerinspanning vereisen. Door SQL-regels en spreadsheets te combineren om processen te documenteren, vergroten organisaties de afhankelijkheid van een groot aantal tabellen met databronnen, attributen en verschillende standaard DQ-regels.
Vaak ziet dit proces er als volgt uit:
- Een business team en data stewards beschrijven de ‘requirements’ (business/DQ rules) in een spreadsheet.
- Vervolgens implementeren ontwikkelaars die business requirements met behulp van SQL of andere programmeertalen in verschillende systemen.
- Wanneer de requirements veranderen, wordt het spreadsheet bijgewerkt en implementeren de ontwikkelaars de regels opnieuw in alle relevante systemen.
- Wanneer een databron wordt toegevoegd, moet een analist de data begrijpen en het ontwikkelingsteam uitleggen welke regels moeten worden geïmplementeerd.
Schalen is op deze manier onmogelijk. Een nieuwe databron toevoegen betekent meer ontwikkelaars toevoegen en meer code onderhouden, wat het totale budget voor de DQM-strategie aanzienlijk kan beïnvloeden. Bij op code gebaseerde Data Quality wordt alles gedaan door ontwikkelaars, en het kan wel een volledige werkdag duren om één enkele regel te implementeren.
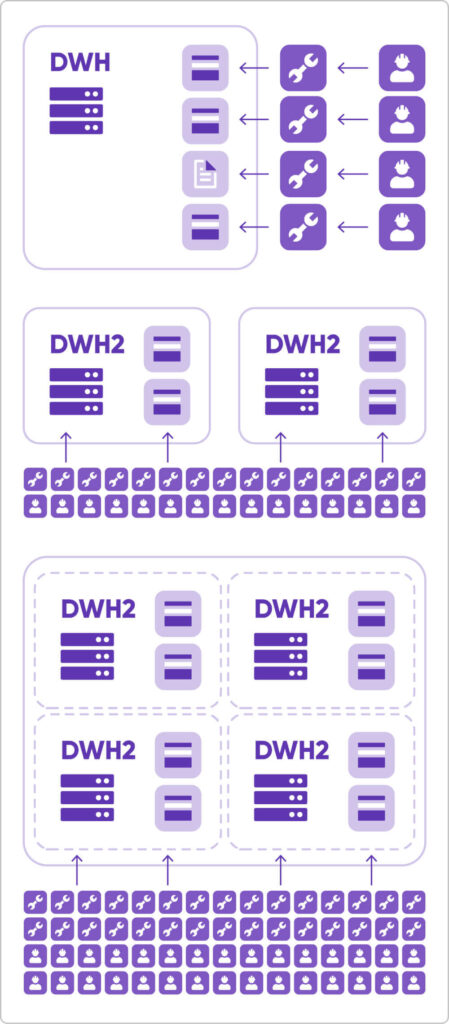
Een handmatige aanpak is sterk afhankelijk van de onderstaande factoren. Zelfs als je ze één voor één aanpakt (wat praktisch onmogelijk is), zullen de kosten nog steeds aanzienlijk stijgen:
- Implementatie van de intiële regels
- Een wijziging in de requirements
- Een schemawijziging in een systeem
- Het aansluiten van een nieuwe databron
Wat is Automated Data Quality?
“AI-gestuurde DQM-automatisering gaat over het gebruik van ingebedde modellen voor ’Machine Learning’ om één of meer DQM-functies betrouwbaar, herhaalbaar en nauwkeurig af te handelen zonder direct menselijk toezicht en hulp.” – James Kobielus, TDWI
Geautomatiseerde, door metadata gestuurde datakwaliteit is een belangrijke volgende stap in de evolutie van datagerichte organisaties. Het is de ruggengraat van een Data Catalog, waarin de actuele versie van de bedrijfsmetadata wordt bijgehouden. Het is een combinatie van AI, en een op regels gebaseerde aanpak om alle aspecten van datakwaliteit te automatiseren: configureren, meten en data aanleveren. Uit onze bevindingen blijkt dat de adoptiegraad van AI-gestuurde/Metadata DQM-automatisering ongeveer 40% bedraagt onder de respondenten van de enquête.
Dit adoptiepercentage heeft een relatie met de omvang en de totale gegenereerde inkomsten van elk bedrijf:
- Meer dan 1 miljard dollar inkomsten: 50% adoptiegraad
- 100 miljoen dollar – 999 miljoen dollar inkomsten: 36% adoptiegraad
- Minder dan 100 miljoen dollar: 23% adoptiegraad
Geautomatiseerde datakwaliteit loont
Op basis van het laatste onderzoek ‘State of Data Quality’ van Ataccama, en dagelijkse gesprekken met klanten wordt duidelijk dat het automatiseren van specifieke processen organisaties kan helpen wanneer ze worstelen met datakwaliteit. Organisaties die een breed scala aan tools implementeren om hun DQM-systemen te moderniseren, zijn succesvoller in het beheren van hun datakwaliteit.
Het komt hier op neer:
Organisaties die succesvol zijn in Data Quality Management hebben gemiddeld 70% van hun processen geautomatiseerd. Bovendien zijn diezelfde organisaties eerder geneigd te investeren in automatisering en modernisering van hun datastack. Dit is een opwaartse spiraal.
Hoe werkt geautomatiseerde Data Quality?
Vergeleken met een traditionele, meer handmatige aanpak is metadata-gedreven Data Quality een complex proces dat uiteindelijk kan worden geautomatiseerd. Maar hoe kunnen bedrijven tot die automatisering komen?
Het eenvoudige antwoord is om dit proces van vier stappen te volgen:
- Catalogiseer uw data door databronnen te verbinden en datadomeinen zoals namen, adressen, productcodes, enz. in kaart te brengen.
- Stel datakwaliteitsregels op voor validatie en standaardisatie en breng ze in kaart voor specifieke bedrijfsdomeinen.
- Automatiseer het ontdekken van metadata: om een nauwkeurig begrip van datadomeinen te behouden, moet je dataprofilering en -classificatie inzetten.
- Herzie voortdurend de definities van datadomeinen, regels voor datakwaliteit en AI-suggesties voor nieuw ontdekte data.
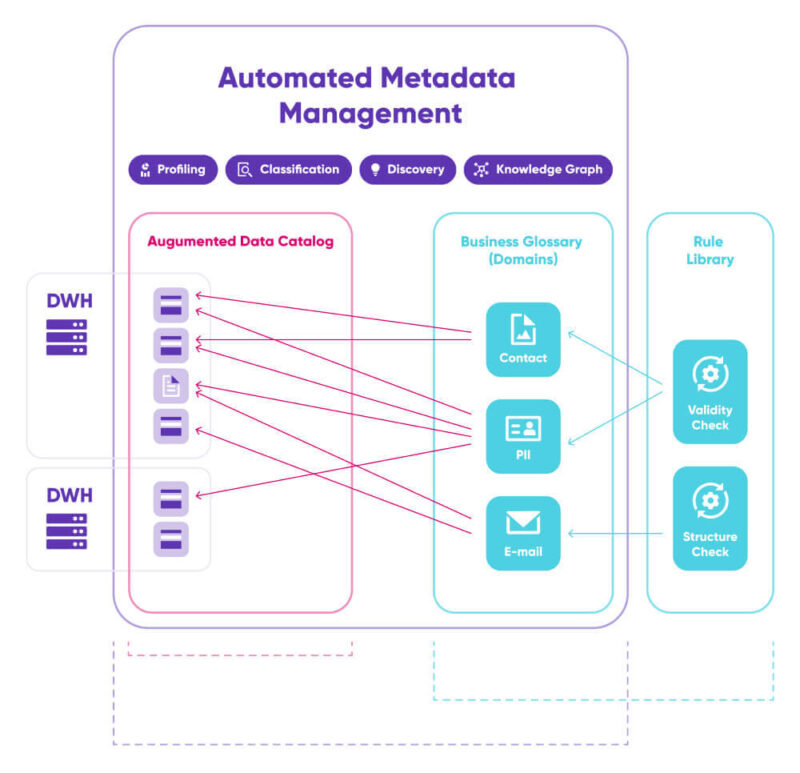
De onderdelen van een geautomatiseerde oplossing voor Data Quality
Data Catalog
Een Data Catalog is de primaire bouwsteen van metadatagestuurd DQM, omdat deze verbindingen met databronnen opslaat, metadata daarover verzamelt en een index van datasassets maakt. Met behulp van geautomatiseerde algoritmen en AI houdt de catalogus de metadata up-to-date en leidt hij nieuwe metadata af. Het is ook de plaats waar geautoriseerde gebruikers snel toegang hebben tot de meest actuele en betrouwbare bedrijfsinformatie.
Centrale ’Rules’- bibliotheek
In een metadata-gedreven systeem wordt Data Quality bewaakt en gehandhaafd door herbruikbare Data Quality regels toe te passen. Idealiter is dit een centrale Rules bibliotheek, een collaboratief ecosysteem waar zakelijke en technische gebruikers deze regels kunnen definiëren en toepassen in no-code of low-code omgevingen.
Business Glossary
In Business Glossaries beschrijven organisaties hun meest essentiële business termen of metadata assets en maken ze afspraken over de betekenis ervan. Dit is cruciaal voor het implementeren van ’automation’. De verbinding met zowel de Data Catalog als de centrale Rules bibliotheek speelt een cruciale rol bij het opslaan van regels voor het detecteren van bedrijfsdomeinen en het maken van mappings van DQ-regels naar die domeinen.
Data profilering
‘Data profiling’ is het analyserende en rekenkundige deel van het systeem. Het detecteert veranderingen in metadata, wijst bedrijfsdomeinen toe aan data en maakt statistieken over data.
De voordelen van geautomatiseerde Data Quality
De noodzaak voor schaalbaarheid en toekomstbestendigheid van je DQM-strategie draait om de toenemende complexiteit en het toenemende volume van data. Je hebt een systeem nodig dat kan schalen en alles kan verwerken, van terabytes tot exabytes aan data, en dat het toeveoegen van steeds meer bronnen aankan. Hier volgen de belangrijkste voordelen van het automatiseren van het verkrijgen van hoogwaardige data met actieve metadata:
Automatisering bespaart tijd
Automatisering zelf is het belangrijkste voordeel omdat het zoveel tijd bespaart. Zodra de data assets verbinding maken met het platform, voert het systeem geautomatiseerde data profilering, -classificatie en onderzoeksprocessen uit. De informatie wordt dan onmiddellijk beoordeeld op basis van nieuw ontdekte of bijgewerkte metadata.
Herbruikbaarheid
Alle configuraties, regels en subroutines zijn herbruikbaar en centraal gedefinieerd in een Rules bibliotheek. U hoeft dezelfde regel niet steeds opnieuw te configureren; de regel zelf moet alleen de logica bevatten, niet de verbinding met de databron.
Minder tijd nodig van mensen
Een geautomatiseerd DQ-proces is afhankelijk van minder mensen. Er zijn geen afzonderlijke datakwaliteitsregels meer die opnieuw moeten worden geconfigureerd door een steeds groeiend team van ontwikkelaars. Het betekent het einde van de handmatige classificatie van data, zoals het koppelen van tabellen aan domeinen en het toevoegen van notities of eindeloos code-onderhoud.
Schaalbaar en toekomstbestendig
Omdat data in complexiteit en volume toenemen, hebben organisaties een systeem nodig dat kan schalen en alle huidige en toekomstige databronnen en datatypen aankan.
Flexibele levering
Met datakwaliteit op basis van metadata kunnen resultaten op elk niveau worden geconsumeerd: van een enkele tabel tot een bedrijfsdomein of een databron. Bovendien kunnen resultaten worden geleverd in batches, real-time of streaming.
Belangrijkste conclusies
Automatisering is de toekomst van datamanagement en metadata spelen daarbij een cruciale rol. Of je nu een dataplatform bouwt zoals een Data Fabric, of net begint met een Data Quality Management implementatie, het gebruik van een metadata-gestuurd DQ systeem is een veel praktischere aanpak. Het bespaart je tijd en laat je herhaalbare datakwaliteitsprocessen sneller implementeren.



