
Er is nog heel veel ongestructureerde data in grote hoeveelheden aanwezig. Het weggooien daarvan is zonde, maar het omzetten van ongestructureerde naar gestructureerde data is een fikse klus. Met kunstmatige intelligentie (AI) kan een groot deel van dit werk geautomatiseerd worden, waardoor deze data heel bruikbaar wordt.
Het belang van een AI-gestuurde datacatalogus
Met de toenemende hoeveelheden data in organisaties zijn data catalogi belangrijker dan ooit. Een datacatalogus is een plek waar stakeholders metadata over alle data-assets uit meerdere databronnen opslaan en delen. De datacatalogus is de juiste plek voor elke analist, ontwikkelaar of dataspecialist die op zoek is naar beschikbare data om te gebruiken in zijn/haar project. Een succesvolle datacatalogus draait om twee belangrijke dingen: automatisering en samenwerking. Automatisering zorgt ervoor dat technische metadata wordt aangevuld met zakelijke metadata, zodat gebruikers meer informatie hebben over een asset. Omdat niet alles automatisch kan worden aangevuld, is het cruciaal om een gebruiksvriendelijke interface te bieden zodat gebruikers sommige metadata handmatig kunnen aanvullen, bespreken en de kennis kunnen delen.
In de Ataccama ONE Data Catalog wordt hiervoor machine learning gebruikt op de volgende manieren:
Suggestie voor zakelijke termen
Een gebruiker voegt een nieuw item toe aan de datacatalogus (bijvoorbeeld een tabel uit een relationele database) om de metadata te verbeteren door business termen toe te wijzen uit een organisatie-brede ‘business glossary’. De definitie van een productcode kan per organisatie verschillen, omdat organisaties verschillende patronen kunnen volgen. Het detecteren van business termen kan eenvoudig worden geautomatiseerd met behulp van reguliere expressies of door data te vergelijken met bepaalde sets referentiedata. Deze aanpak is echter niet erg flexibel. Het weerspiegelt niet de gebruikersinteracties, en matcht alleen dezelfde data (beschreven door dezelfde metadata) met steeds dezelfde reguliere expressie. Op machine learning gebaseerde tagging van business termen kan actief leren van de input van gebruikers en woorden aanbevelen op basis van eerdere gebruiksacties, zonder dat er expliciet vooraf gedefinieerde logica voor het toewijzen van zakelijke termen nodig is. Het systeem herkent de overeenkomsten tussen items in de datacatalogus en doet suggesties voor de toewijzing van business termen op basis van de mate van overeenkomst.
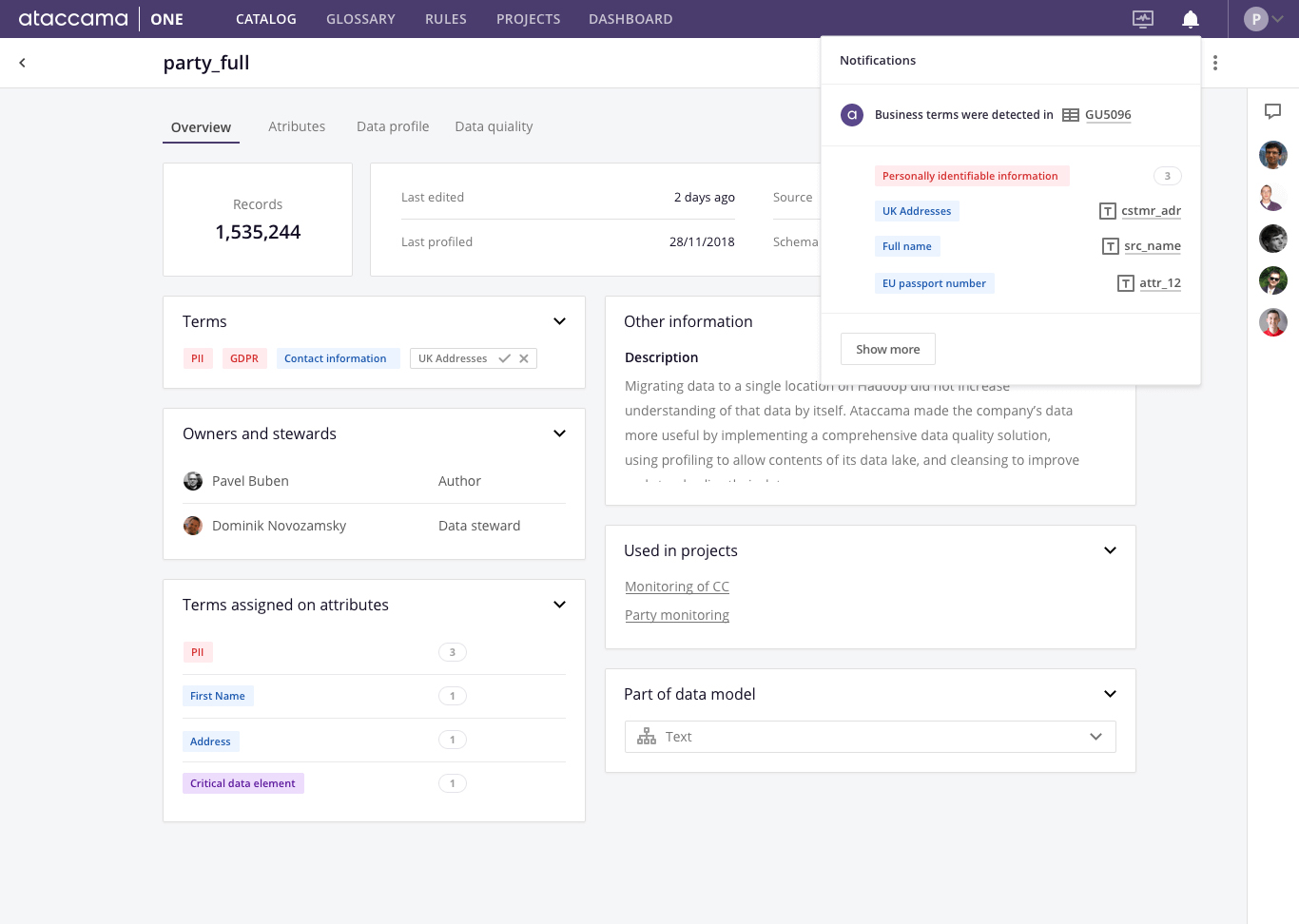
Wanneer je gebruikt maakt van machine learning, kan de datacatalogus actief leren van de input van gebruikers en zo zelf woorden voorstellen.
Relaties ontdekken
Het vermogen van machine learning om vergelijkbare items in een datacatalogus te herkennen, maakt nog veel meer mogelijk. Over het algemeen heeft een organisatie veel gerelateerde data in verschillende systemen. Een gebrek aan mogelijkheden om deze relaties tussen meerdere bronnen formeel vast te leggen ontbreekt echter. Vaak is het door een aantal onafhankelijk gekoppelde en ongedocumenteerde ETL jobs moeilijk om een duidelijk beeld te schetsen van welke data gerelateerd is. Stel je voor dat een groep analisten een project start en een specifieke dataset krijgt. Door een tekort aan informatie over de dataset (waarschijnlijk veroorzaakt door personeelsverloop) zijn ze niet in staat om bepaalde codes in de data te begrijpen (hun dataset bevat bijvoorbeeld een codering die zou kunnen verwijzen naar de beschrijving ervan, en helaas weten ze niet waar ze die kunnen vinden). Met ‘relationship discovery’ kan de datacatalogus vaststellen of de codering verwijst naar een andere dataset binnen de organisatie. Dit geeft de analisten meer relevante informatie over het begrijpen van data en helpt hen nauwkeurigere rapporten te maken.
Gebaseerd op gelijkenisdetectie is de datacatalogus ook in staat om andere relaties dan foreign keys te identificeren. Relaties tussen tabellen in verschillende omgevingen en dubbele data, veroorzaakt door meerdere overlappende uittreksels, kunnen worden geïdentificeerd door een datacatalogus die gebruik maakt van machine learning, en kunnen licht werpen op de overkoepelende data lineage en -structuur van systemen.
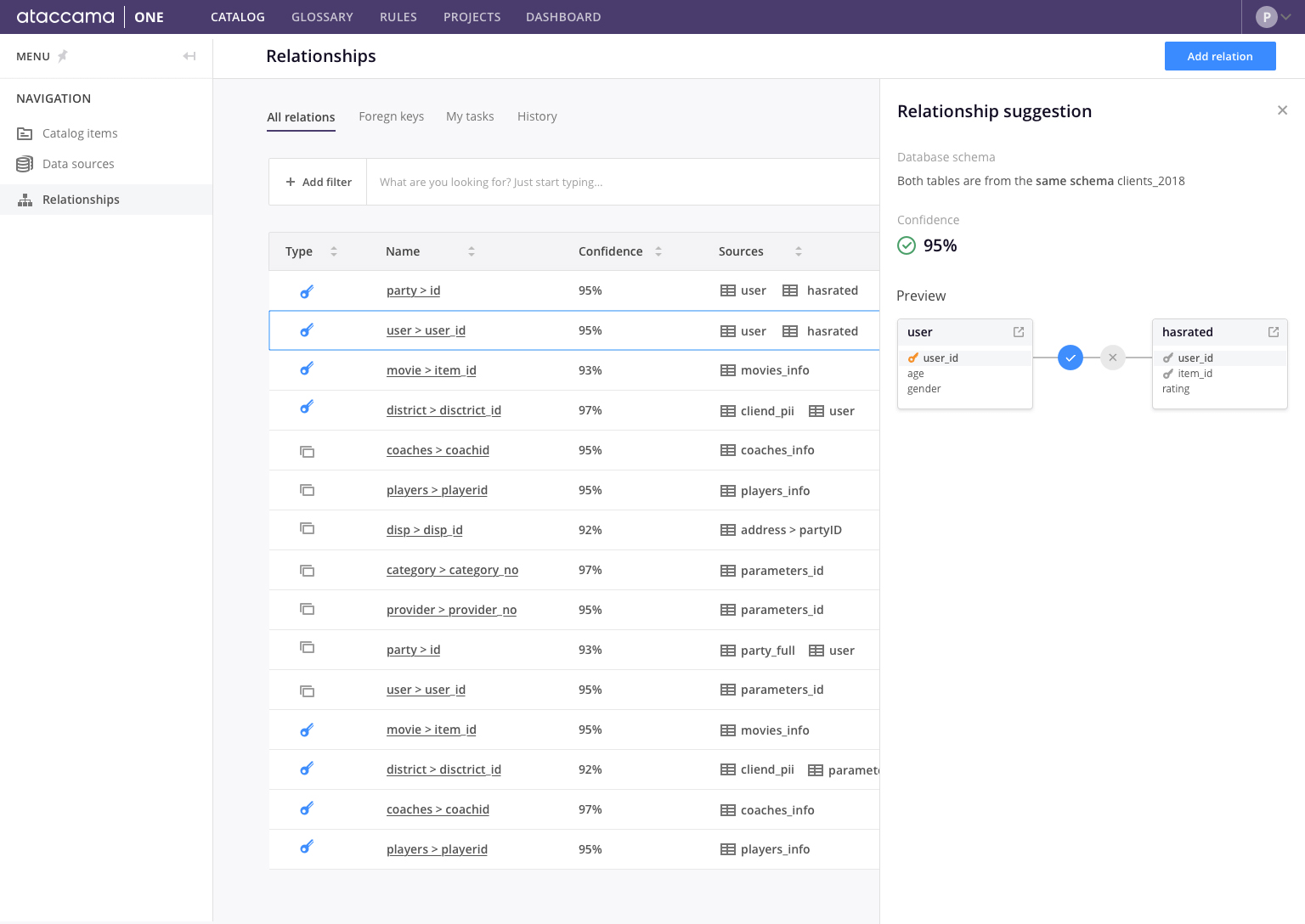
Met relationship discovery kan je de datacatalogus laten bepalen of een attribuut verwijst naar een andere dataset in de organisatie.
MDM optimaliseren met Machine Learning
Een andere mogelijkheid voor de toepassing van machine learning doet zich voor in elke standaard master data management use case. Een belangrijke functie van elke goede MDM-oplossing is het masteringproces. Mastering omvat het verzamelen van data uit meerdere bronnen, het matchen van records die de individuele gevallen van dezelfde entiteit vertegenwoordigen (bijv. dezelfde persoon, hetzelfde organisatie, hetzelfde product), d.w.z. bucketing, en het creëren van het best mogelijke record (bv. golden record) uit elke bucket door ze samen te voegen. Meestal zijn de regels voor bucketing en voor het maken van een golden record handmatig. Vaak moeten de regels deterministisch en volledig transparant (d.w.z. een white box) zijn vanwege wettelijke vereisten, vooral als het gaat om persoonlijke gegevens. Naast het matchen moeten gebruikers record die verkeerd zijn samengevoegd weer handmatig kunnen splitsen. Vanwege al deze eisen worden de regels meestal vooraf geconfigureerd en moeten ze zorgvuldig worden ontworpen.
Bewaken van de performance van regels
In werkelijke scenario’s is het beheer van uitgebreide datasets een iteratief proces. Eerst wordt de data uit verschillende bronnen opgeschoond en samengevoegd. De initiële regels worden voorbereid en het systeem draait op een initiële dataset. De resultaten worden vervolgens onderzocht en de regels worden aangepast, waarna het proces wordt herhaald. De output kan resulteren in veel valse positieven of negatieven. De engine kan bijvoorbeeld per ongeluk records matchen die niet gematcht zouden moeten worden, en het kan records missen die wel gematcht zouden moeten worden. Matching kan automatisch gebeuren, als de regel robuust en betrouwbaar genoeg is; of het kan worden ondersteund door matching voorstellen te produceren die handmatig moeten worden verwerkt. Automatisering is veel minder duur voor een organisatie. Regels voor het matchen zijn meestal behoudend, omdat handmatige splitsingen vanuit zakelijk oogpunt duurder zijn dan handmatige samenvoegingen. Bovendien is het mogelijk om specifieke uitzonderingen te configureren die voorkomen dat bepaalde records worden samengevoegd.
Data stewards lossen matching voorstellen op, behandelen problemen met de datakwaliteit en voorzien hun verbeteringen handmatig van een label. Al deze interacties geven de mogelijkheid om te leren van gebruikersfeedback. Het is mogelijk dat de oorspronkelijke regels na enige tijd in productie niet meer effectief zijn, omdat data dynamische kenmerken heeft. Een matchingsproces zou plotseling waarden in een historisch leeg attribuut kunnen ontdekken, en dat zou heel nuttig kunnen zijn om nauwkeuriger te matchen. Het zou geweldig zijn als het systeem suggesties zou kunnen geven voor het bijwerken van de regels, of het nu gaat om het toevoegen van een nieuwe regel, het verwijderen van een oude regel of het wijzigen van de bestaande regel. De regels zouden overbodig kunnen zijn, of een volgorde van uitvoering van de regels zou de prestaties kunnen beïnvloeden. Het systeem zou dan moeten kunnen helpen om de prestaties van het hele proces te optimaliseren.
Machine learning en anomaliën detectie
De meeste data governance-architecturen bevatten aanzienlijke dataverwerkings jobs die gepland en getriggerd worden door verschillende factoren. Deze jobs omvatten het verplaatsen en transformeren van data, vaak in ketens van meerdere jobs die van elkaar afhankelijk zijn. Het is van groot belang om de status van deze jobs continu te monitoren. Een voorbeeld van waarom dit belangrijk is, is semantische juistheid. Bepaalde jobs kunnen slagen, zelfs als ze op een afwijking stuiten. Stel je een taak voor die een hele dag transactiegegevens verwerkt van een filiaal van een onderneming. Voor dit specifieke filiaal is het gebruikelijk dat er op woensdag veel minder transacties zijn dan op vrijdag, en dat er in het weekend géén zijn. Op een week levert de taak op vrijdag minder data op dan verwacht en de taak op zaterdag wat extra data. De taak faalt misschien niet, maar het gedrag is onverwacht. Machine learning is goed in het voorspellen van redelijke tijdseries (d.w.z. tijdseries met een trend en seizoensgebondenheid). Het is vaak zo dat organisatiesprocessen zich redelijk genoeg gedragen om machine learning modellen te gebruiken voor het detecteren van afwijkingen.
In Ataccama ONE wordt AI gebruikt om afwijkingen in data te detecteren, waaronder veranderingen in datavolumes, uitschieters, veranderingen in de kenmerken van data en meer. De oplossing verbetert in de loop van de tijd naarmate het leert van de benadering van de gebruiker op gerapporteerde anomaliën.
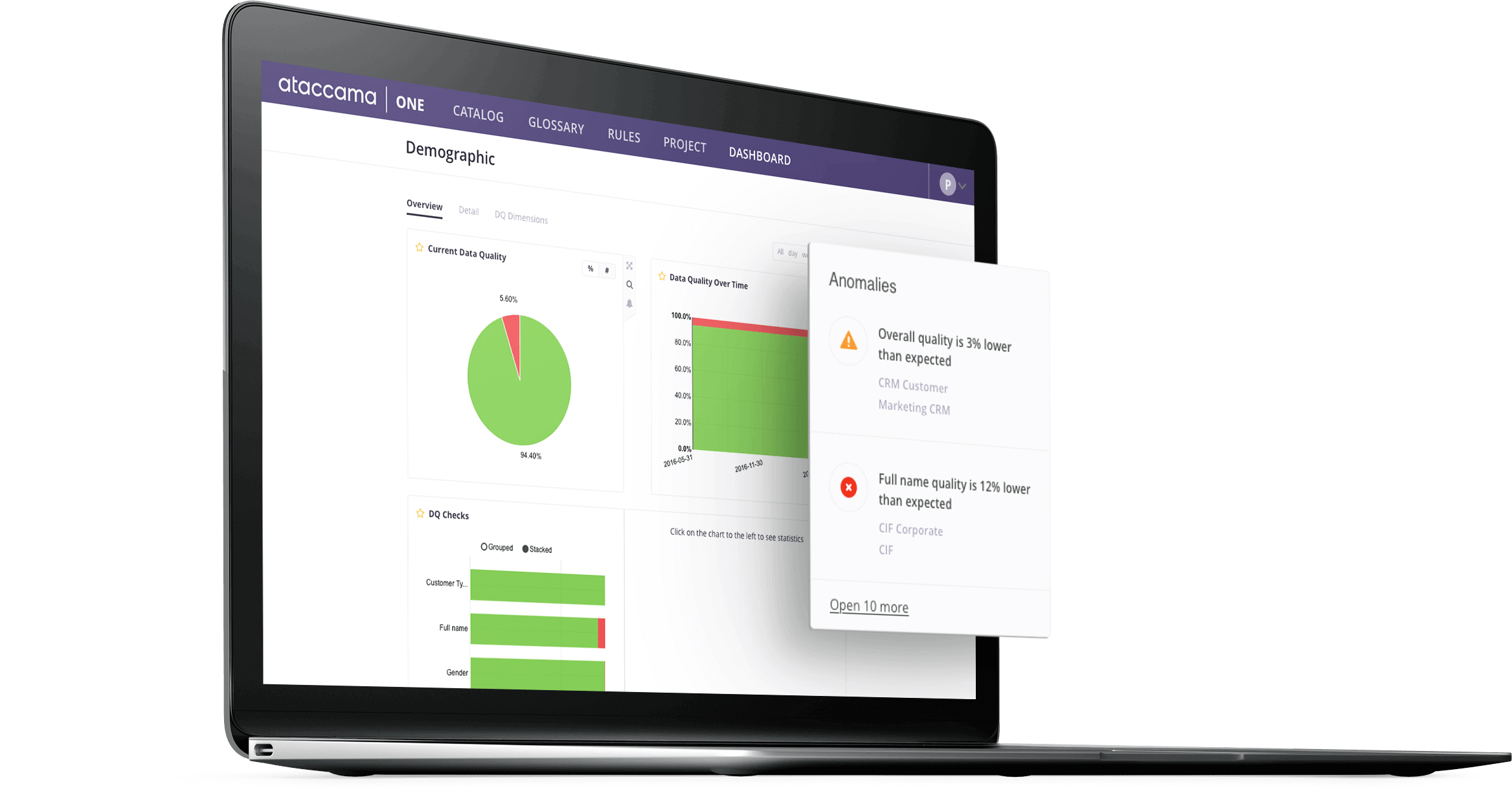
Onregelmatigheden in trends in de datakwaliteit kan je opsporen met anomaliedetectie in de datacatalogus.
Bewaking van datakwaliteit
Een ander voorbeeld van een anomaliedetectie use case is het monitoren van datakwaliteit, waarbij een set handgemaakte regels voor datakwaliteit worden geëvalueerd volgens een gepland tijdschema. Deze regels creëren in de loop van de tijd succespercentages, wat je een tijdreeks geeft voor elk van de regels. Vaak stellen systemen ons in staat om een statische procentuele drempel per regel te definiëren om de data stewards die betrokken zijn bij het proces te waarschuwen als het resultaat onder deze drempel zakt. Maar het gedrag van de uitkomsten is misschien niet zo eenvoudig en het zou helpen om een systeem te hebben dat uit gebruikersinteractie leert wat wel of niet als een anomalie moet worden beschouwd. Het is natuurlijk veel moeilijker om afwijkingen in data te begrijpen en te voorspellen als je niet alleen kwantitatieve variaties in datafeeds observeert, maar ook andere aspecten. In zo’n geval is het noodzakelijk om de gemeenschappelijke oorzaken van plotselinge veranderingen in datakwaliteit te leren kennen, te identificeren en te begrijpen in de bredere context van meerdere databronnen, omdat de onderlinge relaties complexer kunnen zijn. Om dit te bereiken moet de oplossing kunnen leren van de feedback van gebruikers en tegelijkertijd hypotheses kunnen genereren die gebruikers weer kunnen verifiëren en bevestigen of verwerpen.
In de Ataccama ONE Data Quality Management module wordt AI en machine learning gebruikt om informatie over de huidige datakwaliteit van een organisatie direct beschikbaar te houden voor snellere, verbeterde besluitvorming en om slimme, geautomatiseerde monitoring en suggesties voor projectconfiguratie te leveren.
Bewaking van datatoename
Anomaliedetectie kan ook worden toegepast op master data management use cases. Samengevoegde numerieke kenmerken (bijv. aantallen records, statistieken van attribuutwaarden) in delta batches van records die op regelmatige basis worden verwerkt, worden voortdurend bewaakt op afwijkingen. Als sommige van deze kenmerken zich voorspelbaar gedragen en vervolgens op een bepaald moment onverwacht gaan reageren, wordt de verantwoordelijke data steward op de hoogte gesteld om het probleem op te lossen en het systeem interactief te leren omgaan met dat geval om meer nauwkeurigheid te realiseren.
Wat zelfsturend datamanagement voor u kan doen
Het vinden van waardevolle informatie in je data is niet alleen een kwestie van het beschikbaar hebben van grote hoeveelheden data, maar ook van het kunnen vinden van de juiste data wanneer je deze nodig hebt. Daarom is een AI-gestuurde datacatalogus tegenwoordig essentieel in organisaties. Machine learning is niet alleen van vitaal belang bij het ordenen en opslaan van je data, maar het wordt ook een belangrijk onderdeel bij het beheren van records. Het gebruik van machine learning in datamanagement helpt de chaos in data tegen te gaan en zorgt ervoor dat je data geordend, correct en gemakkelijk te vinden is.
Wil je meer weten over wat een Self-Driving Data Management & Governance platform voor je organisatie kan betekenen? Neem gerust contact met ons op voor een vrijblijvende kennismakingsafspraak
Bron: https://www.ataccama.com/blog/how-ai-is-transforming-data-management



