
Analisten zijn het over één ding eens: het is van cruciaal belang om je data om te zetten in bruikbare intelligentie, en de adoptie van Snowflake in de cloud is een geweldige manier om dit te doen. Maar er is een cruciaal metadata-onderdeel dat je eerst moet begrijpen. Laten we eens kijken hoe je Data Lineage kunt integreren met Snowflake.
Waarom automatisering van metadata belangrijk is
Teams die metadata automatiseren voor een dieper contextueel begrip van hun datastromen:
- winnen marktaandeel
- vergroten de bedrijfsflexibiliteit
- beperken risico’s
- beperken blootstelling aan marktvolatiliteit, met verbeterde besluitvorming
De cloud biedt een uitstekende infrastructuur en mogelijkheden voor analytics. Dataplatforms in de cloud kunnen bedrijfsprocessen veilig ondersteunen en schalen zonder de toegang tot de data die je nodig hebt te bemoeilijken, wanneer je deze nodig hebt. En cloudarchitecturen bieden bedrijven bijna onbeperkte rekenkracht, zodat ze hun meest resource-intensieve data projecten kunnen uitvoeren.
Wat is Snowflake?
Snowflake is een op cloudcomputing gebaseerde oplossing voor geïntegreerde dataopslag. Het platform kan worden uitgevoerd op Amazon S3, Microsoft Azure en het Google Cloud Platform.
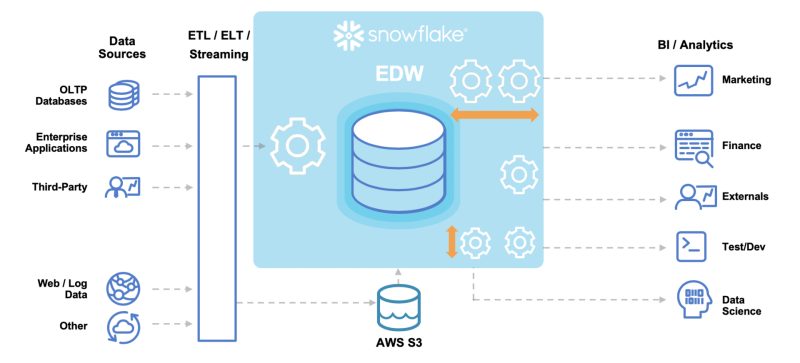 Snowflake biedt ondernemingen functies zoals datawarehouses, datamarts en data lakes, gepresenteerd in een gebruiksvriendelijke interface met één enkele bron van betrouwbare data voor de hele organisatie.
Snowflake biedt ondernemingen functies zoals datawarehouses, datamarts en data lakes, gepresenteerd in een gebruiksvriendelijke interface met één enkele bron van betrouwbare data voor de hele organisatie.
Wat je niet weet, kan je schaden
Het migreren van legacy-systemen of het toevoegen van een nieuwe gegevensbron aan een cloudplatform wordt complex als er geen zicht is op alle datastromen om het proces te begeleiden.

Lineage automatisering kan je helpen inzicht te krijgen. Hiermee vermijdt je het gevaar van het ‘niet weten’ doordat er precies wordt laten zien welke data wordt gebruikt, hoe het wordt gebruikt, waar het vandaan komt en hoe het getransformeerd wordt wanneer het door het systeem stroomt.
Meer inzicht in datastromen met Lineage
Het is een uitdaging om alle datastromen bij te houden die vanuit verschillende bronnen Snowflake binnenkomen. Het kan overweldigend zijn om handmatig de integriteit van data te evalueren, kwaliteit en compromisloze beveiliging te garanderen en impactanalyses uit te voeren om problemen met alle datasets, rapporten en semantiek te voorkomen.
Het automatiseren van het verzamelen van data dat naar Snowflake wordt verplaatst, kan de grootste pijnpunten van de overgang verlichten en de bedrijfsresultaten en migratievoordelen vergroten.
Door MANTA te implementeren in Snowflake kunnen gebruikers de ROI op data maximaliseren en de waardecyclus verkorten, waarbij ruwe data worden geanalyseerd en bruikbare business intelligence wordt geproduceerd. Daarom hebben we besloten om iedereen te helpen door drie belangrijke vragen te beantwoorden
- Hoe migreer ik naar Snowflake met behulp van Data Lineage?
- Waarom zou ik Snowflake uitbreiden met Data Lineage?
- Hoe optimaliseer ik datapijplijnen om de levering van data te versnellen?
Hoe migreer ik naar Snowflake met behulp van data lineage?
Snowflake biedt een enkele bron van waarheid die goed werkt om datasilo’s tussen teams te elimineren, met name tussen technische en zakelijke gebruikers. Wanneer iedereen naar dezelfde data kijkt, is het gemakkelijker om belanghebbenden op één lijn te krijgen, zodat je bedrijf inzichten kan krijgen en besluiten kan nemen op basis van gelijke data.
Als je naar de cloud migreert, moet je werken met databases, tabellen, views, ETL-processen en rapporten. Om deze allemaal met de hand bij te houden is een verloren zaak. Het is onvermijdelijk dat er bij de overgang iets over het hoofd wordt gezien of dat gegevens die niemand gebruikt en die op het punt staan ‘met pensioen te gaan’, worden gemigreerd, wat onnodige kosten en weken van tijdverlies met zich meebrengt.
Door de data-inventaris in kaart te brengen met lineage, krijgen gebruikers duidelijkheid over wat wordt gebruikt, wat moet worden gemigreerd en wat moet worden verwijderd.
Waarom Snowflake aanvullen met data lineage?
Ondernemingen die metadatabeheer en lineage mapping automatiseren, profiteren van verbeterde bedrijfsresultaten op belangrijke gebieden, waaronder:
1) Makkelijke dataworkflow
Lineage biedt datateams een uitgebreid overzicht van alle datastromen, waardoor het eenvoudiger wordt om data-assets te identificeren en te lokaliseren en de efficiëntie en productiviteit van de workflow te verhogen, terwijl er minder tijd hoeft te worden besteed aan het zoeken naar, verifiëren van en het aanvragen van machtigingen voor toegang tot data. MANTA biedt data gebruikers een uitgebreide visuele kaart van hun data.
MANTA kan verbinding maken met de Snowflake-database om automatisch metagegevens van Snowflake te lezen en een gedetailleerde lineagekaart uit te voeren om gebruikers te helpen begrijpen waar data vandaan komen, welke transformaties plaatsvinden in Snowflake en hoe alles downstream wordt beïnvloed.
2) Meer vertrouwen in data
Met geautomatiseerde afstammingsgegevens kunnen teams de afstammingslijn van data herleiden om de nauwkeurigheid en integriteit van data in rapportages of analyses te bevestigen, terwijl de ondersteunende documentatie wordt aangehaald om ervoor te zorgen dat teams met vertrouwen kunnen handelen op basis van de resultaten van bepaalde data-analyses. Naast mensen en processen helpt technologie het vertrouwen in en de betrouwbaarheid van data te versterken en een gezonde datagovernance in de cloud te handhaven.
Lineage kan verschillende gebieden van governance ondersteunen, waaronder het vastleggen van documentatie en protocollen voor welke data verzameld moeten worden en hoe metadata en datamodellen voor de verzamelde middelen geformatteerd moeten worden. Lineage maakt het gemakkelijker om uitschieters te ontdekken en data te corrigeren voordat ze naar beneden doorsijpelen en iets downstream beïnvloeden.
3) Naleving van regelgeving bereiken en behouden
Het automatiseren van lineage helpt bedrijven in sterk gereguleerde sectoren zoals de financiële sector en de gezondheidszorg te voldoen aan voorschriften zoals BCBS239, GDPR en CCPA door te laten zien hoe data door verschillende systemen stroomt van bron naar bestemming, hoe PII (persoonlijk identificeerbare informatie) wordt beschermd, versleuteld en afgeschermd en waar deze wordt opgeslagen in het systeem.
Hoe optimaliseer ik datapijplijnen om de levering van data te versnellen?
Het Snowflake-platform is gebouwd om snelheid en prestaties te optimaliseren. Door computing te scheiden van storage en zero-copy cloning aan te bieden, is Snowflake het eerste dataplatform dat echt de onderliggende infrastructuur biedt om DataOps-teams in staat te stellen dezelfde waarde te leveren die DevOps heeft geleverd voor applicatieontwikkeling in de context van flexibiliteit, onderhoudbaarheid, beveiliging en governance.
Met gestroomlijnde data pipelines zien teams minder fouten en minder gebroken rapporten. Maar als het toch gebeurt, is het opsporen van de fout een gestroomlijnd proces met geautomatiseerde lineage. Een geautomatiseerde lineage kan knelpunten en bugs bij de implementatie en configuratie verminderen, zodat technische teams zich kunnen richten op het versnellen van de levering en de nauwkeurigheid van datagestuurde inzichten voor het bedrijf in plaats van op het onderhouden van de infrastructuur.
Door geautomatiseerd metadatabeheer te implementeren met het MANTA-platform, kunnen Snowflake-gebruikers profiteren van volledige zichtbaarheid van de pijplijn om de complexiteit van de omgeving te verwijderen en samenwerking en self-service voor zowel zakelijke als technische gebruikers mogelijk te maken. De interface van MANTA codeert data in kleur om het opnemen van informatie te vergemakkelijken en visuele overbelasting te voorkomen.
