
Als het gaat om het opsporen van data van lage kwaliteit, zijn er twee belangrijke benaderingen die organisaties hanteren: ‘rule based’ bewaking van de datakwaliteit en AI/ML-gestuurde anomaliedetectie.
Datakwaliteitsregels zijn een geweldige manier om specialistische kennis in je datasysteem te injecteren. Die kennis is echter slechts zo goed als de specialist die de regel maakt. Bovendien vergen datakwaliteitsregels onderhoud en inzet van mensen om ze in verschillende systemen in te zetten.
AI daarentegen werkt autonoom en detecteert problemen waarvoor je normaal gesproken geen regels zou schrijven. Maar AI kent zijn eigen problemen. Het is slechts zo goed als de data die je erin stopt, en het kost tijd om te inleren en af te stemmen. De beste aanpak combineert daarom beide methoden in een systeem dat alle ongewenste data van lage kwaliteit opspoort.
Het beste van twee werelden
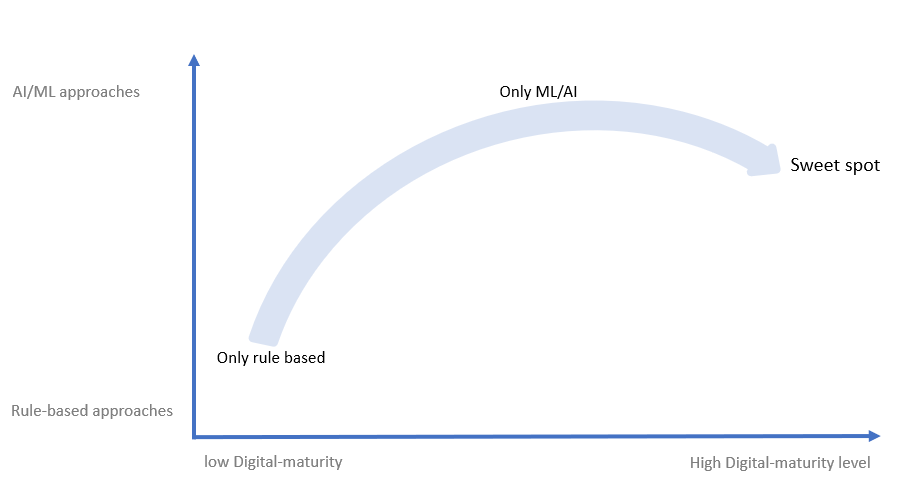
Naarmate organisaties groeien in hun digitale transformatie, erkennen ze het belang van AI en machine learning-technologieën voor het beoordelen van datakwaliteit en anomaliedetectie. De organisaties met een lage digitale volwassenheid kiezen voornamelijk traditionele benaderingen. Dit zijn op datakwaliteitregels gebaseerde trajecten. Naarmate ze volwassener worden, verschuiven ze naar AI- en ML-modellen en richten zich daar nadrukkelijk op. De optimale volwassenheid treedt echter op wanneer bedrijven de noodzaak inzien van een evenwicht tussen ‘rule-based’ en AI/ML-benaderingen, waarbij ze toch meer neigen naar AI/ML vanwege de autonome en adaptieve aard van deze benadering.
Voor het bereiken van goede Data Observability (bekijk hier een workflow) is bijvoorbeeld een combinatie van beide nodig.
De methode gebaseerd op datakwaliteitsregels is nog steeds essentieel, omdat je hiermee data kunt valideren en transformeren volgens bestaande vereisten. Dit omvat use cases die te belangrijk of te specifiek zijn om aan de AI alleen over te laten. Bijvoorbeeld het valideren van data tegen een lookup van toegestane of niet toegestane waarden, het controleren en standaardiseren van dataformats voor het data warehouse, of het controleren van het aantal lege waarden in een specifieke kolom.
Aan de andere kant is AI effectief in het ontdekken van real-time problemen in data, het vinden van complexe relaties en het vinden van problemen in data die je niet zou verwachten of waar je normaal geen regels voor schrijft.
Het combineren van ’rule-based’ en AI/ML-methoden is de beste keuze om data van hoge kwaliteit te garanderen. Laten we nu ingaan op de specifieke voor- en nadelen van elke aanpak.
1. Rule-based aanpak
De meest gebruikte methode voor het controleren/valideren van data is een op datakwaliteitsregels gebaseerde aanpak. Deze aanpak is fundamenteel voor het beheer van data. Het was een van de eerste manieren waarop mensen de kwaliteit van data controleerden.

Voordelen van de op regels gebaseerde aanpak
Gemakkelijk te interpreteren
Het is makkelijker om een ruleset te lezen en te begrijpen (en waarom mogelijke fouten worden geregistrerd) dan beslissingen van AI.
Flexibel/bewerkbaar
Regels kunnen handmatig worden verwijderd, toegevoegd of gewijzigd. Het is veel ingewikkelder om de interne werking van een AI-algoritme te veranderen.
Externe kennis en naleving
Wanneer zich nieuwe voorschriften voordoen (zoals die van de GDPR), kan je die onmiddellijk opnemen in je ’rules library’. Dit geldt ook voor alle expliciete (externe/interne) kennis. Het is veel gemakkelijker om die in je rules library vast te leggen dan je AI/ML te trainen om ze zelfstandig te spotten. Bijvoorbeeld, een nieuwe verordening zegt dat de belasting in een gebied met lage inkomens niet meer dan 20% mag bedragen. Je zou dan de regel “Belasting < 20%” kunnen invoeren.
Nadelen van de op regels gebaseerde aanpak
De op datakwaliteitsregels gebaseerde aanpak heeft een aantal duidelijke tekortkomingen, vooral vanwege de handmatige aard ervan, die veel werk vergt van specialisten en data stewards.
Zware afhankelijkheid van domeinexpertise
De regels zijn slechts zo goed als de expertise van degene die ze schrijft. Ze leunen in hoge mate op de deskundigheid van domeinexperts, personen die nauw betrokken zijn bij de data en bepaalde verwachtingen hebben van de kwaliteit ervan.
Dit beperkt het aantal mensen dat kan bijdragen aan de verbetering van de datakwaliteit. Met de groei van datavelden en de opkomst van data lakes kan zelfs een expert die de organisatie (en de data) begrijpt, misschien niet elke regel definiëren die in de toekomst problemen bij de invoer van data kan identificeren.
Stel bijvoorbeeld dat je in de banksector een regel wilt maken voor transactielimieten (hoeveel geld je in één keer kan versturen). In werkelijkheid zouden niet alle klanten dezelfde beperkingen mogen hebben. Je zou verschillende vragen moeten beantwoorden om regels te maken. Vragen zoals: hoe haal je de optimale limiet voor verschillende klanten eruit? Hoe zorg je ervoor dat deze limieten veranderen als de klant langer klant is en zijn kredieten ook veranderd?
Regels vereisen onderhoud
Hoewel de op regels gebaseerde aanpak flexibel kan zijn, vergt het handmatige werk (veel energie en tijd) om je rules library te wijzigen en te onderhouden. Regelgebaseerde benaderingen zijn statisch en kunnen alleen evidente onregelmatigheden opsporen. Dergelijke regels zijn misschien in het verleden opgesteld, op basis van oudere inzichten. Ze worden niet doorontwikkeld, passen zich niet aan en zijn misschien minder relevant voor nieuwe data.
Stel bijvoorbeeld dat je een regel definieert dat een maximale transactie minder dan 100.000 moet zijn (d.w.z. x <€100.000). Echter, na groei van het bedrijf en meer high-profile accounts, maken klanten regelmatig dat soort transacties en worden ze niet langer gezien als uitschieters.
Het maken en onderhouden van regels vergt veel tijd en energie. Het handmatig doorzoeken van data (kolom voor kolom) kan ongelooflijk traag zijn. Bovendien moet de specialist die de regels schrijft volledig op de hoogte zijn van alle beleidsvoorschriften en wijzigingen van het bedrijf, en zich dus voortdurend inlezen en bijwerken om ervoor te zorgen dat de regels relevant blijven.
Dit constante onderhoud en het onvermogen om je aan te passen aan veranderende datasets leiden tot problemen bij het opschalen van de rule-based aanpak. Gebrekkige communicatie kan daarnaast leiden tot onnodige regels of zonder uitleg: het is een uitdaging om dit soort regels op de juiste manier aan te passen zonder te begrijpen waarom ze überhaupt zijn opgesteld.
Het ontdekken van relaties is moeilijker
De opkomst van big data met verschillende dimensies heeft het opstellen van datakwaliteitsregels over datadoorsnedes bijna onmogelijk gemaakt. Stel je voor dat je een tabel met 200 kolommen hebt. Het zou bijna onmogelijk zijn om regels te definiëren die op al die kolommen van toepassing zijn (met zoveel variatie is een enkele regelset achterhaald). Je zou ook individuele regels kunnen maken voor elke doorsnede maar ook dat zou enkele beperkingen hebben. Denk aan de verschillende relaties die deze kolommen met elkaar hebben – zowel die waarvan we ons van bewust zijn als die waarvan we ons niet bewust zijn (misschien groeit kolom x mee met y, maar alleen als z onder een bepaalde waarde ligt). AU zou deze relaties automatisch kunnen ontdekken, terwijl als we er individueel regels voor op zouden stellen, deze relaties misschien genegeerd worden en een cruciaal verband tussen de data gemist zou worden.
Denk bijvoorbeeld aan een gedetailleerde record van klantdata. Je kunt kolommen hebben voor leeftijd, inkomen, adres, geslacht, enz. Misschien is er een verband tussen mensen die in een bepaald gebied wonen, een bepaalde leeftijd hebben en een bepaald inkomen hebben. Het vinden van zo’n verband tussen de kolommen zou handmatig ingewikkeld zijn. Je zou elke kolom moeten profilen, individuele regels moeten opstellen, en dan dit patroon zelf moeten opmerken. AI kan deze relaties automatisch ontdekken zodra je hem een dataset geeft.
2. AI/ML anomaliedetectie
AI/ML-methodes benaderen Data Quality door datasets te profilen, patronen te vinden en vervolgens die patronen te gebruiken om onverwachte of “afwijkende” waarden in nieuwe data te vinden. Het verhelpt de nadelen van op regels gebaseerde controles van de datakwaliteit door gebruikers in staat te stellen het hele proces van controle van de datakwaliteit onmiddellijk te automatiseren en onbekende en onverwachte problemen in hun data op te sporen.

Voordelen van AI/ML Anomaliedetectie
Real-time inzichten/aanpassingsvermogen
Als de data in realtime verandert, past de AI zich tegelijkertijd aan. Terwijl je met regels eerst zou moeten herkennen dat deze verandering heeft plaatsgevonden (veel gemakkelijker te doen met AI) en vervolgens een regel zou moeten aanpassen of schrijven om deze aan te pakken.
AI/ML-modellen kunnen bijvoorbeeld aanpassen wat zij als abnormaal beschouwen naarmate je bedrijf groeit. Stel dat je een bank hebt die gewoonlijk 1.000 transacties per uur heeft, en je AI herkent alles boven de 5.000 als abnormaal. De AI zal dat aantal voortdurend aanpassen van 5 naar 10 tot 20.000, afhankelijk van het aantal transacties dat de bank uitvoert. Je hoeft niet elke zes maanden een nieuwe regel te schrijven om rekening te houden met de groei.
Weinig onderhoud nodig
Zodra de AI je systeem leert kennen, zou het autonoom moeten kunnen werken.
Kan onbekende problemen identificeren
Zoals we in de nadelen van de rule-based aanpak aangaven, kan AI complexe relaties tussen data (of kolommen in de data) signaleren die mensen misschien over het hoofd zien. Bijvoorbeeld, het realiseert zich dat al je klanten die in een bepaald gebied wonen een inkomen hebben van minder dan 100.000 dollar per jaar. Het kan dan klanten markeren die melden dat ze in dat gebied wonen, maar aanzienlijk meer verdienen.
Nadelen van AI/ML-anomaliedetectie
Deze modellen kunnen complex zijn om te implementeren en tijd en moeite kosten om effectief te worden en je data volledig te begrijpen. Je zult verschillende modellen moeten uitproberen; sommige zullen beter presteren dan andere. Zelfs de modellen die goed werken, moeten worden afgestemd, de prestaties moeten worden geëvalueerd en er is geduld nodig voordat ze volledig autonoom worden op uw systeem. Hier volgen enkele nadelen van de AI-aanpak.
Vereist veel data van hoge kwaliteit
In een van onze vorige artikelen bespraken we het belang van datakwaliteit bij het bouwen van een AI.Deze modellen hebben grote hoeveelheden data nodig om ervoor te zorgen dat ze je systeem nauwkeurig weergeven. Ze hebben echter zulke grote hoeveelheden data nodig omdat de kwaliteit vaak niet hoogwaardig is. Als je hoge eisen aan datakwaliteit stelt, hebben deze modellen minder data nodig, omdat de kleinere hoeveelheid van hoge kwaliteit nog steeds je datasets als geheel vertegenwoordigen.
Als je een paradox ziet, zit je op het juiste spoor. Hoe vindt je data van hoge kwaliteit om een AI te bouwen die precies dat moet doen – je datakwaliteit verbeteren? Het antwoord bestaat uit twee delen en hangt af van de vraag of je AI ‘supervised’ of ‘unsupervised’ is.
- Beheerde AI-modellen: Gesuperviseerde AI-modellen hebben gelabelde data nodig. Een tag of label moet aangeven wat iets is (of niet) voor uw use case. Voor anomaliedetectie heeft een beheerd AI-model labels nodig om “normale” data te onderscheiden van “abnormale” data om te leren wat wat is. Zodra het van deze labels heeft geleerd, kan het deze automatisch toepassen op nieuwe datasets en zelf afwijkende entiteiten vinden. Uiteraard is dit sterk afhankelijk van een goede labeling van je datasets.
- Onbeheerde AI-modellen: Soms hebt je echter geen toegang tot al die gelabelde data en moet je AI zelfstandig leren van je datasets. Bij anomaliedetectie vereist deze use case dat je verschillende veronderstellingen maakt over de dataset. De eerste en belangrijkste is dat de meeste gegevens in die set “normaal” zijn en slechts enkele “afwijkend”. Dit kan een nadeel zijn, want als deze veronderstelling onjuist is, kan dat leiden tot een foute AI. Daarom is het beter om grotere datasets te gebruiken, omdat je dan meer kans hebt dat de meeste entiteiten “normaal” zijn en niet “afwijkend”.
Verklaarbaarheid
Een van de grootste nadelen van AI is dat het een “black-box” is. Er is veel onzekerheid in het bedrijfsleven, watbesluitvorming erg moeilijk maakt. Gebruikers hebben datamodellen nodig om die onzekerheid te verminderen, niet om nog meer dubbelzinnigheid toe te voegen! Daarom verwachten ze dat AL/ML-modellen de efficiëntie verhogen, maar tegelijkertijd begrijpbaar en verklaarbaar zijn. Een van de belangrijkste uitdagingen is dus hoe AI/ML-modellen te ontwikkelen die heel uitgebreid zijn. Veel AI-modellen bieden echter oplossingen of suggesties zonder enige uitleg over hoe ze daar zijn gekomen, waardoor ze moeilijker te vertrouwen zijn voor zakelijke gebruikers die hun fundamentele werking niet begrijpen.
Optimale prestaties kosten tijd
Terwijl DQ-regels tijdrovend zijn omdat ze niet dynamisch kunnen veranderen of zich kunnen aanpassen aan de data, vergt het opzetten en autonoom uitvoeren van AI ook behoorlijk wat tijd. Na de implementatie moet u de AI zorgvuldig controleren, kijken welk model het beste werkt, input leveren en de resultaten enige tijd evalueren voordat de AI je systeem goed genoeg kent om deze taken zelfstandig uit te voeren. Je kunt wel een model implementeren dat vrijwel onmiddellijk “werkt”. Wil het echter “goed werken” (met hoge nauwkeurigheid), dan heeft de AI tijd nodig om je data te leren kennen en moet je het model bijstellen om ervoor te zorgen dat het geen kritieke informatie mist (zoals nieuwe regelgeving of organisatiebeleid).
Conclusie
We zien nu dat de rule based aanpak makkelijk te gebruiken en aan te passen is, maar veel inspanning en handwerk vergt. AI-oplossingen kunnen daar het antwoord op zijn maar hebben ook nadelen wat betreft complexiteit en implementatie.
De beste aanpak is om beide oplossingen met elkaar te combineren. Wij geloven in het leveren van beide benaderingen en het ondersteunen van organisaties bij het vinden van hun ‘sweet spot’ op basis van volwassenheid en digitale evolutie. Daarom biedt de Data Catalog van Ataccama geïntegreerde evaluatie-instrumenten voor datakwaliteit en anomaliedetectie, waarmee je anomalieën kunt signaleren met behulp van AI-benaderingen en DQ-regels kunt instellen, allemaal op één plek.



